Abstract
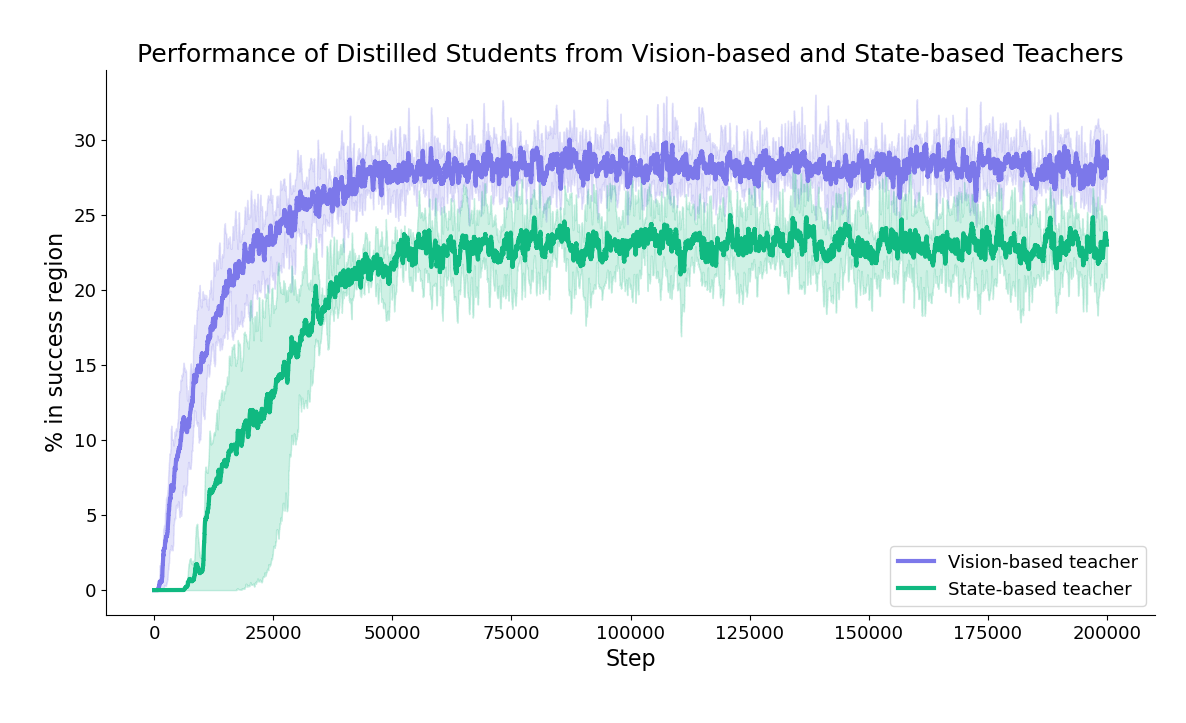
This work explores techniques to scale up image-based end-to-end learning for dexterous grasping with an arm + hand system. Unlike state-based RL, vision-based RL is much more memory inefficient, resulting in relatively low batch sizes, which is not amenable for algorithms like PPO. Nevertheless, it is still an attractive method as unlike the more commonly used techniques which distill state-based policies into vision networks, end-to-end RL can allow for emergent active vision behaviors. We identify a key bottleneck in training these policies is the way most existing simulators scale to multiple GPUs using traditional data parallelism techniques. We propose a new method where we disaggregate the simulator and RL (both training and experience buffers) onto separate GPUs. On a node with four GPUs, we have the simulator running on three of them, and PPO running on the fourth. We are able to show that with the same number of GPUs, we can double the number of existing environments compared to the previous baseline of standard data parallelism. This allows us to train vision-based environments, end-to-end with depth, which were previously performing far worse with the baseline. We train and distill both depth and state-based policies into stereo RGB networks and show that depth distillation leads to better results, both in simulation and reality. This improvement is likely due to the observability gap between state and vision policies which does not exist when distilling depth policies into stereo RGB. We further show that the increased batch size brought about by disaggregated simulation also improves real world performance. When deploying in the real world, we improve upon the previous state-of-the-art vision-based results using our end-to-end policies. To our knowledge, this is the first work that has demonstrated end-to-end RL for dexterous grasping with multifingered hands.
Contributions
- First sim-to-real with multifingered hands using end-to-end RL training.
- Improved simulation infrastructure to scale up vision-based training.
- State of the art results for vision-based grasping.